Service Management
This section shows how a deployed VS stack can and should be interacted with.
Scaling
Scaling is a handy tool to ensure stable performance, even when dealing with higher usage on any service. For example, the preprocessor and registrar can be scaled to a higher replica count to enable a better throughput when ingesting data into the VS.
The following command scales the renderer service to 5 replicas:
docker service scale <stack-name>_renderer=5
A service can also be scaled to zero replicas, effectively disabling the service.
Warning
The redis and database should never be scaled (their replica count
should remain 1) as this can lead to service disruptions and corrupted data.
Updating Images
Updating the service software is done using previously established tools. To update the service in question, it needs to be scaled to zero replicas. Then the new image can be pulled, and the service can be scaled back to its original value. This forces the start of the service from the newly fetched image. Another option to keep the service running during the upgrade procedure is to sequentially restart the individual instances of the services after pulling a newer image using a command:
docker service update --force <stack-name>_<service-name>
Updating configurations or environment files
Updating the service configurations or environment files used can not be done just by rescaling the impacted services to 0 and rerunning. The whole stack needs to be shut down using the command:
docker stack rm <stack-name>
A new deployment of the stack will use the updated configuration. The above mentioned process necessarily involves a certain service downtime between shutting down of the stack and new deployment.
Inspecting reports
Once a product is registered, a xml report containing wcs and wms getcapabilities of the registered product is generated and can be accessed by connecting to the SFTP service via the sftp protocol.
In order to log into the logging folders through port 2222 (for vhr18, emg and dem have 2223 and 2224 respectively) on the hosting ip (e.g. localhost if you are running the dev stack) The following command can be used:
sftp -P 2222 <username>@<host>
this will direct the user into /home/<username>/data sftp mounted directory which contains the 2 logging directories : to/panda and from/fepd
Note
The mounted directory that the user is directed into is `/home/user`, where user is the username, hence when changing the username in the .conf file, the sftp mounted volumes path in docker-compose.<collection>.yml must be changed respectively.
Inspecting logs in development
All service components are running inside docker containers and it is therefore possible to inspect the logs for anomalies via standard docker logs calls redirected for example to less command to allow paging through them.
docker logs <container-name> 2>&1 | less
In case that only one instance of a service is running on one node, the <container-name> can be returned by fetching the available containers of a service on that node with a command
docker logs $(docker ps -qf "name=<stack-name>_<service-name>") 2>&1 | less
It is possible to show logs of all containers belonging to a service from a master node, utilizing docker service logs command, but the resulting listing does not enforce sorting by time. Although logs of each task appear in the order they were inserted, logs of all tasks are outputted interleaved. To quickly check latest time-sorted logs from the service, sorting the entries by timestamp column, do:
docker service logs <stack-name>_<service-name> -t 2>&1 | sort -k 1 2>&1 | tail -n <number-of-last-lines> 2>&1 | less
The docker service logs is intended as a quick way to view the latest log entries of all tasks of a service, but should not be used as a main way to collect these logs. For that, on production setup, an additional EFK (Elasticsearch, Fluentd, Kibana) stack is deployed.
Inspecting logs in production
Fluentd is configured as main logging driver of the Docker daemon on Virtual machine level. Therefore for other services to run, Fluentd service must be running too. To access the logs, interactive and multi-purpose Kibana interface is available and exposed externally by traefik.
For simple listing of the filtered time-sorted logs as an equivalent to docker service logs command, a basic Discover app can be used. The main panel to interact with the logs is the Search bar, allowing filtered field-data and free-text searches, modyfing time range etc. The individual log results will then appear in the Document table panel in the bottom of the page.
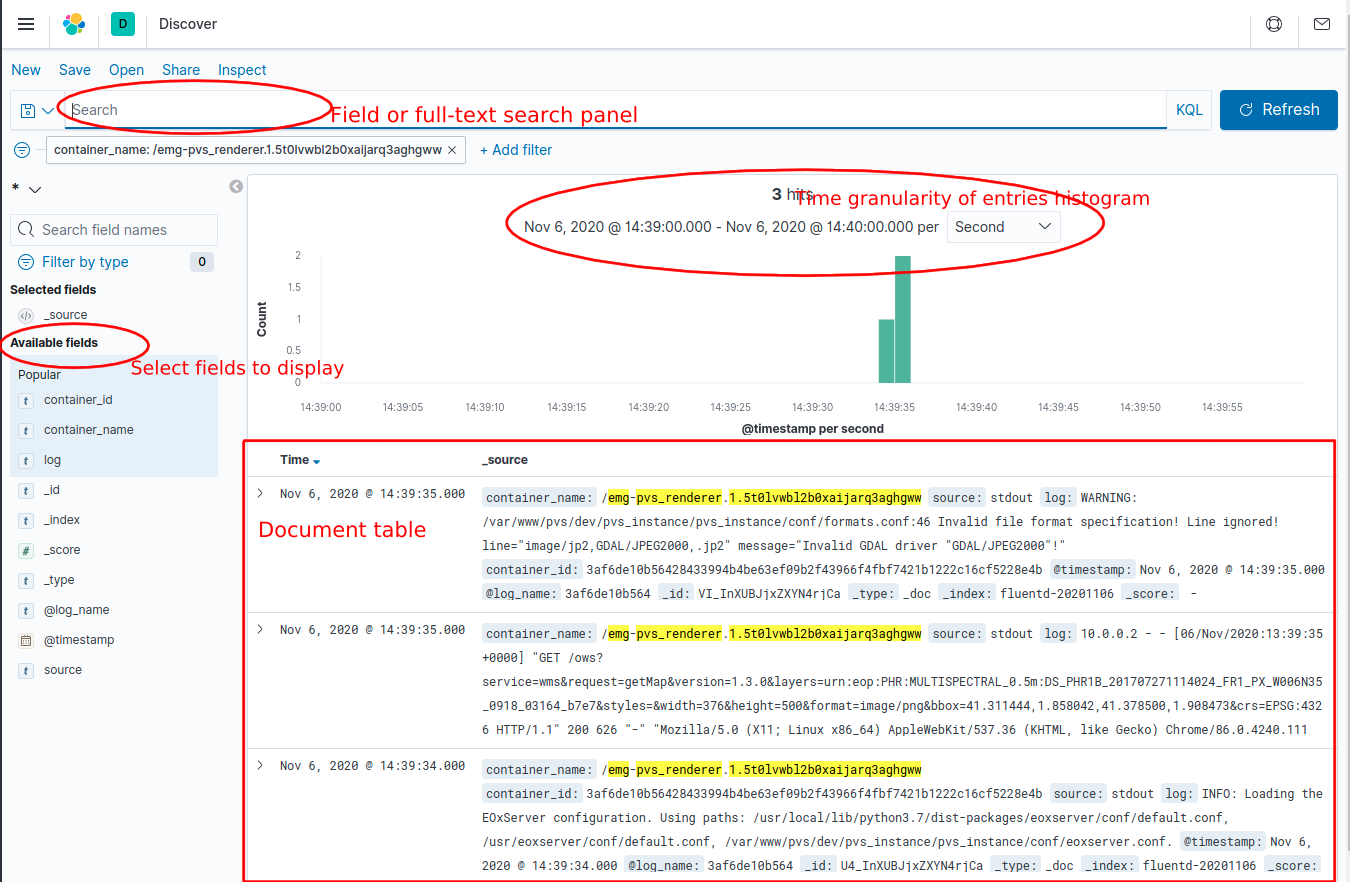
Figure 2 Kibana discover panel
For specific help with Discover panel, please consult Kibana official documentation
In order to select any other option from the Kibana toolkit, click the horizontal lines selection on the top left and pick a tool.
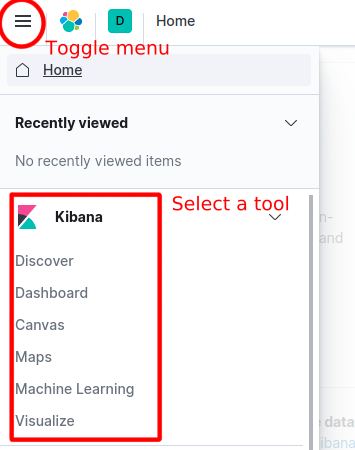
Figure 3 Kibana menu
Kibana also allows to aggregate log data based on a search query in two modes of operation: Bucketing and Metrics being applied on all buckets.
These aggregations then are used in Visualisations with various chart modes like vertical bar chart, horizontal line chart. Using saved searches improves the performance of the charts due to limiting the results list.
Increasing logging level
In default state, all components are configured to behave in production logging setup, where the amount of information contained in the logs is reduced. Different components contain different ways to increase the reported logging level for debugging purposes.
In order to increase logging level of EOXServer component, and therefore of each service, which depends on it, a DEBUG configuration option contained in file $INSTALL_DIR/pvs_instance/settings.py needs to be set to True. This setting needs to be applied on each node, where there is a running a service for which the DEBUG logging should be enabled, as it is stored in the respective docker volume <stack-name>_instance-data, which is created per node.
A restart of respective service for the change to be applied is also necessary. In order to change the DEBUG settings on an example of a renderer, do
docker exec -it $(docker ps -qf "name=<stack-name>_renderer") bash
cd ${INSTALL_DIR}/pvs_instance
sed -i 's/DEBUG = False/DEBUG = True/g' settings.py
In order to increase logging level of registrar and preprocessor services to DEBUG, the respective Python commands need to be run with an optional parameter –debug.
Ingestor service by default logs its messages in DEBUG mode.
The cache services internally uses a Mapcache software, which usually incorporates an Apache 2 HTTP Server. Due to that, logging level is shared throughout the whole service and is based on Apache .conf file, which is stored in $APACHE_CONF environment variable. To change the logging level, edit this file, by setting a LogLevel debug and then gracefully restart the Apache component (this way, the cache service itself will not restart and renew default configuration).
docker exec -it $(docker ps -qf "name=<stack-name>_cache") bash
sed -i 's/<\/VirtualHost>/ LogLevel debug\n<\/VirtualHost>/g' $APACHE_CONF
apachectl -k graceful
Cleaning up
Current configuration of the services does not have any log rotation set up, which means that service logs can grow significantly over time, if left not maintained and set on verbose logging levels. In order to delete logs older than 7 days from a single node, a following command can be run
journalctl --vacuum-time=7d
Additionally in order to delete older logs from docker containers present on a node, keeping only a certain number of newest rows, a following command can be run.
truncate -s <number rows to keep> $(docker inspect -f '{{.LogPath}}' $container 2> /dev/null)
The final section Data Ingestion explains how to get data into the VS.
Database backup
The database can be backed up with the script below. The STACK and BACKUP_PATH variables can be changed depending on the stack and desired path of backup files
#!/bin/bash
# Variables to be changed
STACK="dem"
BACKUP_PATH="/path/to/backup/storage"
# Script variables
FILE_NAME="$(date +'%Y%m%d').sql.gz"
DB_SERVICE=""$STACK"_database"
DB_CONTAINER="$(docker ps -l -q -f name=^/$DB_SERVICE)"
echo "Backing up $STACK stack"
echo "Backup path: $BACKUP_PATH"
echo "Backup file: $FILE_NAME"
echo "Backup service: $DB_SERVICE"
echo "DB container id: $DB_CONTAINER"
echo "Backing up to /$FILE_NAME"
docker exec $DB_CONTAINER sh -c "pg_dump -U "$STACK"_user -d "$STACK"_db -f c > /$FILE_NAME"
echo "Copying to $BACKUP_PATH"
docker cp $DB_CONTAINER:/$FILE_NAME $BACKUP_PATH
echo "Cleaning up"
docker exec $DB_CONTAINER sh -c "rm /$FILE_NAME"
To restore from a backed up file run the below script. Here the STACK, DATE and BACKUP_PATH can be changed. Note: Date for last backup must be in YYYYMMDD format
#!/bin/bash
# Variables to be changed
STACK="dem"
DATE="20210722"
BACKUP_PATH="/path/to/backups"
# Script variables
BACKUP_FILE="$BACKUP_PATH/$DATE.sql.gz"
UNCOMPRESSED_FILE="$BACKUP_PATH/$DATE.sql"
DB_SERVICE=""$STACK"_database"
DB_CONTAINER="$(docker ps -q -f name=$DB_SERVICE)"
echo "Restoring $STACK stack"
echo "Backup file: $BACKUP_FILE"
echo "Backup service: $DB_SERVICE"
echo "DB container id: $DB_CONTAINER"
echo "Unpacking $BACKUP_FILE"
gunzip $BACKUP_FILE
echo "Copying unpacked file"
docker cp $UNCOMPRESSED_FILE $DB_CONTAINER:/
echo "Restoring database"
docker exec $DB_CONTAINER sh -c "psql -U "$STACK"_user -d "$STACK"_db < /$DATE.sql"
echo "Cleaning up"
docker exec $DB_CONTAINER sh -c "rm /$DATE.sql"
rm $UNCOMPRESSED_FILE